03 服务端重构总结
花费了差不多1个多月的时间,任天赋、王帅琪和我三人功共同完成了隐私信息管理系统的前后端代码的重构工作。
其中,王帅琪独立完成了前端代码的重构工作,任天赋负责服务端代码中大部分“写”的操作以及与第三方平台对接的代码工作,我负责的是服务端代码中绝大部分与前端对接的“读”的操作以及与隐私合规平台预设规则对接的代码工作。
下面谈一谈我在进行重构过程中的体会和看法。
重构的原因
之所以进行重构,是因为之前的系统虽然能够继续开发,但是因为代码结构和业务逻辑的原因,后续维护难度会越来越大,我理解的主要的问题是:
- 代码结构比较自由,服务端逻辑比较分散,难以维护,可读性不好
- 有硬编码的现象,前端、后端维护分别维护同一份数据的配置文件,容易出现问题
- 数据库字段设计不统一,导致增加了大量的处理逻辑
- 前端负责了很多数据二次处理的工作
重构就是为了解决问题,所以针对上面的问题,这次重构的思路是:
- 选用Egg框架代替Koa,代码使用一套统一的约定进行开发,让逻辑尽量清晰
- 数据相关的配置文件由后端维护,变化较大的存入数据库,有必要的以接口的形式返回给前端
- 优化数据库的字段设计,结合相关的配置文件,减少不要的处理逻辑
- 服务端完成绝大部分的数据处理工作,以较规范的REST接口形式将数据返回给前端,前端可以直接展示数据
框架选型
在重构之前,我针对BFF进行了调研,针对几种Web开发框架进行了对比,比较可行的方案就是Egg和Koa(Express),最后之所以选择用Egg代替了Koa作为框架进行开发,主要基于以下几个原因:
- Egg是在Koa的基础上进行的封装,完全兼容Koa的中间件,并且文档比较友好
- 是蚂蚁金服的最佳实践的封装,有众多的插件支持,配套完善
- Egg更适合于企业开发,以约定代替配置,可以做到代码规范的统一,提高代码的可维护性
Koa比Egg更加灵活,这就导致了代码无论怎么写,都能够运行,并且很多配套的支持都需要自行搭配,而Egg提供了一整套的解决方案,更适合有严格要求、长久更新维护的企业项目,也更能做到渐进增强的研发体验。当业务开发到一定程度时,完全可以由Egg抽象、封装出属于特定业务、特定模式的中间件、插件甚至框架。
使用了Egg,感觉最大的好处有两个:
(1)大量的约定
大量的约定,既限制了开发者,又给开发者自由。
在Egg的约定下,MVC的架构非常清晰,目录结构合理,可以按需选择。
1 | egg-project |
根据它的约定进行开发,开发者不再需要关心哪些功能应该放在哪里、哪些服务应该如何被调用。当团队的开发者都遵循统一的约定时,就不必关心这些事情,只关心如何实现具体的业务逻辑,因为其他的事情Egg都帮你做好了
(2)完善的功能
Egg是针对企业级研发的框架,所以它也提供了很多企业级应用开发的核心功能,比如单元测试、本地调试、日志,异常处理等等,封装了cookie和session的操作,我们只需要按照它的文档进行配置,就可以实现绝大部分的需求。
以断点调试为例,其他的框架可能还需要手动去进行浏览器或者IDE的配置,而Egg则实现起来非常简单,就是将启动命令由npm run dev改为npm run debug,
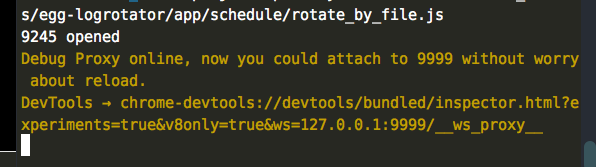
然后用浏览器打开控制台输出的Devtools后面对应的地址即可于凯的进行debugger、打断点的调试了:
非常的容易。
除了框架直接提供的功能之外,也可以使用很多第三方的插件来帮助我们实现功能,比如参数校验和异常处理,使用egg-validate可以大大的简化我们在Controller中的参数校验的逻辑:
1 | // 查询网络上传全部详细信息的校验规则 |
当然,Egg作为这么一个功能丰富、大而全的框架,使用中也是有一些问题,后面会提到。
配置处理
前面说了,之前可能同一份配置文件,比如加密方法,可能前后端都要维护,如果新增一种加密方法的话,可能前后端都需要更改代码,而且也容易由于维护的不一致性,导致bug。
所以这次重构,将这种配置文件都拿到了服务端,在config目录下,将我们业务所需要的配置文件全部放到custom的目录下,然后通过config.default.js导入
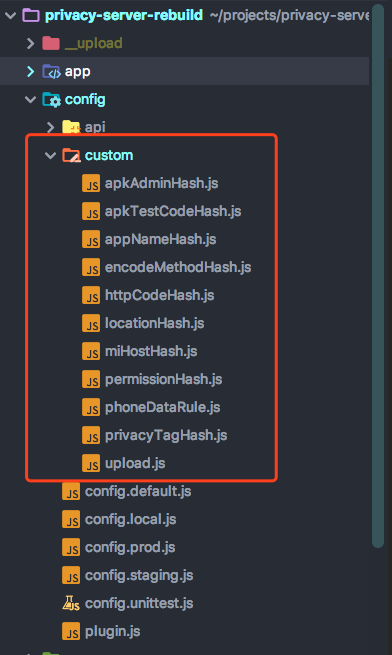
使用时,服务端直接通过this.config就可以获取到对应的配置文件,而前端如果需要对应的配置文件,则直接提供了一个接口提供数据
这样不仅只需要维护一份配置文件,而且如果相关数据更改时,只需要到这里更改一次,不用在所有代码中搜寻进行更改,避免了不优雅的硬编码的现象。
优化数据库的字段
这个部分实际上我没有什么发言权,因为我的经验、水平和对业务的熟悉程度都不太够,而且业务是不断变化的,需求不断增加,很有可能导致当初设计的字段,在后期不满足需要。而想要设计出比较完美且扩展性良好的数据结构,不是一件容易的事情。
现实中,当原始的数据结构与需求冲突,后期解决起来会很麻烦,导致很多复杂的处理逻辑。
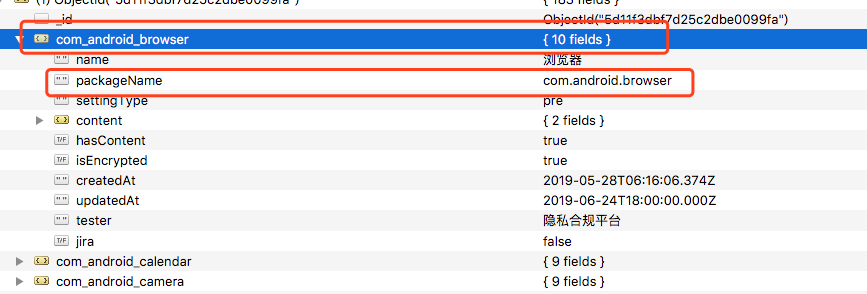
举个例子,系统中获取到的被检测的包名是是以.分割的,比如com.android.browser,而Mongo数据库的存储对象的键值是不能有.的,原来是将com.android.browser改为了com_android_browser进行存储,这样改过来改过去就需要进行字符串的处理,如果遇到一些特殊的本来就含有_包名还需要特殊处理
这次重构,我和任天赋约定,所有的包名都使用com.android.browser存入数据库,由于大部分情况都是存入到Gzip压缩后的数据,所以没有关系,而必须作为key时,只在他写的时候进行处理替换,而且我们在预设规则的数据表里增加了packageName字段,用来存放com.android.browser,这样实现通过配置关系与com_android_browser对应,能够减少一部分处理的逻辑,而且剩余的处理逻辑比较集中
其他的还有一些细节的优化,比如Log和网络请求的加密信息存储结构改为一致的等等。
我们之所以能够对数据库字段进行更改,很大的原因是因为隐私管理系统的历史数据相对不那么重要,如果我们提供一个缓冲器,之前的数据就可以不再关注。若非如此,想要实现这一点的优化是不太好处理的,因为要考虑大量的兼容性的问题。而且虽然这次重构通过优化可能带来了一些好处,但是也许随着需求的出现,优化后的字段又面临新的问题。所以说这是很考验水平的事情。
为前端提供处理好的数据
之前的代码中,前端从接口获取数据后,还是要进行很多的处理才能展示在UI上。而BFF的理念就是,一个前端配药一个小的数据处理后端,减轻前端处理数据的逻辑,让前端的中心关注在交互逻辑和UI呈现上。这次的重构也是相当于BFF的一次事件,只不过大部分数据直接从数据库获取,而不是调用其他后端的接口和服务获取到的而已。
秉承着这个理念,服务端重构的代码基本上把数据按照前端UI界面的格式、按照前端同事的要求,通过接口提供给前端。前端拿到数据后处理的逻辑会很少。
比如前端展示标记后的Log信息和网络请求,之前是前端根据隐私值对信息标记,重构之后由服务端根据隐私项将信息进行标记,标记的方式是通过和前端约定好的标签的形式,返回标记好的信息,前端根据m属性拿到加密方法,直接找到对应的CSS样式,展示即可
1 | /** |
此外,作为比较典型的前后端分离的项目,前后端之间唯一的交互就是通过接口。接口设计尽量靠近REST规范,通过不同的HTTP方法来区分请求的种类和目的:
1 | // 预设规则 |
通过规定统一的响应格式和引入egg-errors插件,实现了接口成功时数据格式以及失败时错误响应的统一格式。既实现了简洁明了的响应结构,又便于前端通过HTTP状态码进行异常处理。
现有的很多其他后台开发的服务端的接口并没有做到严格遵守REST的规范,或者说没有向这个方向努力,我们在尽力做到规范和标准。(这里也要向王帅琪同学学习,虽然刚毕业,但是能力很强,提出的建议很中肯,对接口的规范性帮助很大。)
之所以能够做到针对前端提供符合要求的数据格式,除了把项目重构、让项目更好的美好愿景之外,另一个原因就是都是组内的同事,沟通更加顺畅且和平,而且都是前端出身,都知道拿到服务端返回一坨面条样的、直接从数据库取回来的数据时的无奈。
所以这也是BFF除了减轻前端数据处理的负担之外最大的好处,就是减少了前后端的撕逼。一些小的数据改动,不再需要后端,我们自己通过Node中间把层微服务提供的数据处理好,返回给自己负责的前端,这流程实在Peace and Love。
改进的空间
虽然是重构了,但是仍然有很大改进和反思的空间
(1)关于Egg
前面提到了Egg的一堆好处,确实,对于开发企业级应用来说,Egg确实是非常易用的。但是也因为此,它变的很厚重,很多功能、很多配置我们并不见得用得上,目前是完全没有问题的。
这就像是我们只要吃一个手抓饼,但是它给我们端上来法式大餐的全套餐具。能吃吗?没问题,但是有可能有一些浪费。更好的方式还是应该针对Egg进行定制,抽象出属于自己的团队和业务的开发框架。
还有一点可能就是它对于类的支持,任天赋开发时采取了面向对象,以类为基础的开发模式,将不同的类型的数据抽象为不同的类,挂到了ctx对象上,这样有助于抽象不同数据对象的行为,代码的可读性更好。
但是在通过context.js挂载时,没有办法获取到Egg的实例,因为只有已函数的形式挂载才能获取到Egg实例,而以导出的类的形式挂载是不行的,结果导致没有办法获取Egg实例上挂载的配置文件。
这一点还是让人很不爽的。Egg支持并鼓励在service中互相调用方法,但是当我们想把拥有相同的行为和方法的一类数据抽象为一个Class时,使用起来却不太方便。
虽然最后通过在config.default.js将配置直接挂到global上解决了这个问题,但是还是让人感到不爽。后面可能还需要研究一下,使我们的使用姿势不太对,还是它本身就不欢迎这种形式。
1 | module.exports = appInfo => { |
(2)关于性能
现在读取数据时,在数据量较大的时候,由于需要解压数据,再加上数据处理的过程,接口响应时间比较长,性能表现不是很好。
后期当性能成为瓶颈时,是否可以考虑引入Redis等缓存来实现查询速度的提高,或者在存储检测结果时进行处理(因为检测时对时间长短不敏感)。
(3)关于开发流程
文档记录在Wiki,Bug通过微信截图反馈,Bug修复情况我们自己记录在Wiki,问题修复后的测试流程也是缺失的。
可能是项目和团队的特殊性吧,但是每当上线代码时,还是觉得忐忑,因为基本没有测试,记录也无处查询。
(4)关于业务
对于这个系统,重构之前的代码逻辑是阻碍新人接受的原因之一,另外一个原因就是比较复杂的业务逻辑。前者通过重构可以解决,后者我认为还是没有很好的解决。
对于重要的项目,如果能有一个比较详尽的业务流程图解+合理的文档+合理的代码注释+合理的代码结构,我想才真的算得上可维护的、健康发展的项目。
重构,对于项目负责人,或者说团队负责人,应该能站在更高的角度,向项目成员介绍(或者以文档的形式)整个业务的逻辑,从大局的角度上把握项目的发展、进行项目的规划。团队成员对整个业务流程和逻辑有了更清晰的了解后,才能更好更快的进行项目开发的流程。
作为项目参与者的我,这方面做的也不太好。因为对比较复杂的业务逻辑不熟悉,服务端开发经验比较少,我的主要关注点在于如何在重构时实现这个功能点、那个功能点,一点点增加对业务的了解,最后止于自己的开发范围,范围之外的业务逻辑还是不太了解。
自己应该更主动的去了解全部的业务,才能更好的理解代码,以后接手也会容易些。
总结
我个人觉得,这次服务端的代码重构,在保证原有系统的功能的基础上,实现了代码的重构,简化了代码逻辑,提高了代码的可读性和维护性,并且实现了新的需求,总体来说还是成功的,能够留下一些经验。
经过重构之后,我觉得,项目对于业务团队的发展还是很重要的,代码的质量也和代码的可维护性有关系,还是应该关注这些东西,关注基础和细节的东西,而且在重要项目的初始规划、设计应该更为慎重,后续开发的代码的质量、代码的规范,应该更为关注。
做好平时的积累,让代码能够长久的维护,推迟不得不重构那一天的到来。
重构能够提高经验,但是平时的积累和细节的关注,也是水平不断提高的方向之一。
以上是我的愚见,让各位大神见笑了。